Fetching Time records from ActiveCollab API

Challenge: Create an Excel report detailing time spent and estimated work from Active Collab
Solution: Utilize the ActiveCollab API to gather the necessary data
ActiveCollab is a tool that helps teams work better together. It lets you manage projects, track time, talk with your team, and handle bills all in one place.
This tool was made in 2007 by two people, Ilija Studen and Goran Radulovic, because they needed a better way to manage their own freelance work. Now, it helps over 50,000 companies around the world. ActiveCollab has different plans based on how many people use it, from a free plan for small projects to bigger plans for large teams.
In our blog post, we’re going to show you how to get time records from ActiveCollab using a Python script. This is important for teams that need to know how much time is spent on projects for billing or to see how work is going.
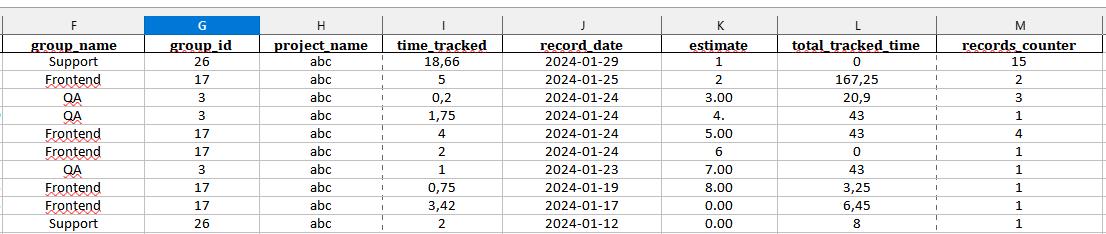
Data structure
Active Collab data structure outlined represents a collection of time records, which is designed to store detailed information about individual time tracking entries associated with tasks or projects. Let’s focus on the most essential parameters:
- is_trashed, trashed_on, trashed_by_id: These fields relate to whether the record has been deleted or moved to trash, including when this occurred and who did it.
- billable_status: Shows whether the time recorded is billable (1) or not.
- value: The amount of time recorded, typically in hours.
- record_date: The date when the time was recorded, presented as a timestamp.
- user_id, user_name, user_email: Information about the user who recorded the time, including their ID, name, and email.
- parent_type, parent_id: The type of the parent item (e.g., Task) and its unique identifier, linking the time record to a specific task.
- created_on, created_by_id, created_by_name, created_by_email: Details about when the record was created and by whom.
- updated_on, updated_by_id: Information on the last update to the record and the user responsible for it.
- project_id: The ID of the project to which the time record belongs.
- job_type_id: An identifier for the type of job or category the time record falls under.
- source: Indicates where the time record was created from, such as the task sidebar.
{
"id": 279408,
"class": "TimeRecord",
"url_path": "/projects/306/time-records/279408",
"is_trashed": false,
"trashed_on": null,
"trashed_by_id": 0,
"billable_status": 1,
"value": 0.25,
"record_date": 1701734400,
"summary": "",
"user_id": 6,
"user_name": "John Doe",
"user_email": "john@example.com",
"parent_type": "Task",
"parent_id": 137932,
"created_on": 1701780184,
"created_by_id": 6,
"created_by_name": "John Doe",
"created_by_email": "john@example.com",
"updated_on": 1701780184,
"updated_by_id": 6,
"project_id": 306,
"job_type_id": 7,
"source": "task_sidebar",
"original_is_trashed": false,
"invoice_item_id": 0
}
Python script
We’ll explore a Python script designed to help us pull time tracking information from ActiveCollab. This tool is perfect for anyone needing to monitor project times closely, especially useful for project managers and anyone involved in billing.
We’ll start by setting up our environment, including loading necessary libraries and accessing your ActiveCollab credentials. Following that, we’ll authenticate with ActiveCollab’s API to obtain a token, which is our key to fetching project and time tracking details.
Our script is smartly built to not just fetch this data but also organize it efficiently. Finally, we compile all this detailed information into a comprehensive report, saved in Excel spreadsheet.
Setup and Configuration
After importing libraries, we load up our environment variables from a .env file. This is a secure way to manage sensitive information like your ActiveCollab email, password, and account name, so you don’t have to put them directly in your script.
We then define the start and end dates for the period we’re interested in tracking, making sure to set the timezone to UTC for consistency. Finally, we construct the URL we’ll use to access the Active Collab API, dynamically inserting the account name to customize the endpoint to your specific Active Collab domain.
import requests
import pandas as pd
from sys import exit
from dotenv import load_dotenv
import os
from datetime import datetime, timezone
import json
import time
# Load environment variables from .env file
load_dotenv()
# Get credentials from environment variables
email = os.getenv("ACTIVECOLLAB_EMAIL")
password = os.getenv("ACTIVECOLLAB_PASSWORD")
ac_name = os.getenv("ACTIVECOLLAB_NAME")
start_date = datetime(2024, 1, 1, tzinfo=timezone.utc)
end_date = datetime(2024, 1, 31, 23, 59, 59, tzinfo=timezone.utc)
# Replace these with your actual Active Collab API credentials and URL
api_url = f"https://mydomain.{ac_name}.com/api/v1"Authentication
We start the process of connecting to ActiveCollab’s API by authenticating ourselves to obtain a token, which is crucial for accessing the protected resources. We make a POST request to the API’s token issuance endpoint, sending our credentials in JSON format.
With the token in hand, we set up the headers for our subsequent API requests. Next, we use these headers to fetch a list of projects from Active Collab.
# Authenticate and get the token
auth_response = requests.post(f"{api_url}/issue-token", json={
"username": email,
"password": password,
"client_name": ac_name,
"client_vendor": ac_name
})
# Check the response's status code
if auth_response.status_code == 200:
try:
# Attempt to parse the JSON if the status code indicates success
auth_response_data = auth_response.json()
token = auth_response_data['token']
# Headers to be used for subsequent API requests
headers = {
"X-Angie-AuthApiToken": token,
"Content-Type": "application/json"
}
# Fetch the list of projects
projects_response = requests.get(f"{api_url}/projects/for-screen?view=list", headers=headers)
projects_data = projects_response.json()Data fetching from Active Collab API and processing it
After successfully fetching a list of projects using ActiveCollab’s API, the script sets parameters for the type of data it’s interested in.
Key Steps Explained
Setting Parameters: A dictionary named params is created to define the criteria for the reports we want to generate. It specifies that we’re interested in assignments that include tracking data and subtasks, and that these should be grouped by project. The date filter is set to ‘any’, indicating no specific date filtering at this stage.
Preparing for Data Collection: Before looping through each project, the script initializes an empty list (projects_reports) to store the data for project reports and a counter (total_time_records) to keep track of the total number of time records processed. Another empty list (all_data) is prepared to hold all the detailed data fetched in the upcoming steps.
Fetching Time Records: With the customized parameters, the script makes a request to the Active Collab API endpoint responsible for running reports. It seeks to obtain all time tracking entries relevant to the current project within the specified dates.
Processing Time Records: The script loops through the response, extracting time tracking details for each entry. It constructs a detailed record for every time entry, including information like the project ID, task ID, task name, the person who logged the time, and the amount of time tracked, among other details.
# Fetch the list of projects
projects_response = requests.get(f"{api_url}/projects/for-screen?view=list", headers=headers)
projects_data = projects_response.json()
params = {
"type": "AssignmentFilter",
"include_tracking_data": 1,
"include_subtasks": 1,
"group_by": "project",
"date_filter": "any",
}
# Initialize an empty list to store project report data
projects_reports = []
total_time_records = 0
all_data = []
# Loop through all projects
for project in projects_data:
project_id = project['id']
project_name = project['name']
print(f"Handling project: {project_id} {project_name}")
start_date_str = start_date.strftime('%Y-%m-%d')
end_date_str = end_date.strftime('%Y-%m-%d')
# Parameters for reports
params_time_records = params.copy()
params_time_records['tracked_on_filter'] = f'selected_range_{start_date_str}:{end_date_str}'
params_time_records['type'] = 'TrackingFilter'
params_time_records['type'] = 'TrackingFilter'
params_time_records['include_all_projects'] = 'false'
params_time_records['type_filter'] = 'time'
params_time_records['project_filter'] = f'selected_{project_id}'
report_time_records = requests.get(f"{api_url}/reports/run", headers=headers, params=params_time_records)
report_time_records = report_time_records.json()
# Loop through each project in the JSON
all_time_record_details = []
if (report_time_records):
for project_key, project_value in report_time_records.items():
# Extract the project_id from the project_key (assuming it's formatted like "project-{id}")
project_id = project_key.split("-")[-1] # Extract the numeric part
# Loop through each record in the project
for record in project_value.get("records", []):
# Gather data from each time record
record_date_datetime = datetime.fromtimestamp(record.get('record_date', ''))
time_record_details = {
'project_id': project_id,
'task_id': record.get('parent_id',''),
'task_name': record.get('parent_name', ''),
'person': record.get('user_name', ''),
'user_id': record.get('user_id', ''),
"group_name": record.get('group_name', ''),
"group_id": record.get('group_id', ''),
'project_name': record.get('project_name', ''),
'time_tracked': record.get('value', 0),
'record_date': record_date_datetime.strftime('%Y-%m-%d'),
'estimate': 0,
'total_tracked_time': 0,
'time_records_counter': 0
}
total_time_records += 1
all_time_record_details.append(time_record_details)Merge Time Records: we focus on refining the time tracking data we’ve collected by merging records that are essentially about the same task done by the same person within the same project. The aim here is to consolidate multiple entries of time tracked into a single record for each unique task-person combination, making the data cleaner and more manageable.
## Merge time records that match (group by task, person)
merged_records = {}
# Loop through each record in all_time_record_details
for record in all_time_record_details:
# Create a unique key for each task based on project_id, task_id, and person
unique_key = (record['project_id'], record['task_id'], record['user_id'], record['group_id'])
if unique_key in merged_records:
merged_records[unique_key]['time_tracked'] += record['time_tracked']
merged_records[unique_key]['time_records_counter'] += 1
else:
# Initialize a new entry in merged_records
merged_records[unique_key] = record.copy() # Copy to avoid mutating the original
merged_records[unique_key]['time_records_counter'] = 1
all_time_record_details = list(merged_records.values())Fetch Additional Details: Here we’re getting ready to gather more details about each project’s tasks, specifically looking at how much time was planned for them and how much time was actually spent.
# Now, gather estimates and tracked_time (all_time)
params_time_records2 = params.copy()
params_time_records2['name'] = 'null'
params_time_records2['project_filter'] = f'selected_{project_id}'
params_time_records2['user_filter'] = 'anybody'
params_time_records2['task_list_filter'] = 'any'
params_time_records2['label_filter'] = 'any'
params_time_records2['start_on_filter'] = 'any'
params_time_records2['due_on_filter'] = 'any'
params_time_records2['created_by_filter'] = 'anybody'
params_time_records2['created_on_filter'] = 'any'
params_time_records2['delegated_by_filter'] = 'anybody'
params_time_records2['completed_by_filter'] = 'anybody'
params_time_records2['completed_on_filter'] = 'any'
params_time_records2['group_by'] = 'dont'
params_time_records2['include_subtasks'] = '0'
params_time_records2['include_tracking_data'] = '1'
params_time_records2['type'] = 'AssignmentFilter'
report_time_records2 = requests.get(f"{api_url}/reports/run", headers=headers, params=params_time_records2)
report_time_records2 = report_time_records2.json()
# save_json_with_timestamp(report_time_records, project_id, 'data/time_records2_')
## Fill in estimation, and total tracked_time
tasks_details_map = {}
if (report_time_records2):
for assignment_id, assignment in report_time_records2["all"]["assignments"].items():
# Construct a unique key based on project and task name or any other suitable unique combination
# Here, we just use task name for simplicity
unique_key = int(assignment_id)
tasks_details_map[unique_key] = {
"estimated_time": assignment["estimated_time"],
"total_tracked_time": assignment["tracked_time"]
}
# Now, loop through all_time_record_details and update the estimate and tracked time
for detail in all_time_record_details:
# Determine the unique key for lookup, again using task name as an example
unique_key = int(detail['task_id'])
# Update the estimate and tracked time if there's a match
if unique_key in tasks_details_map:
detail['estimate'] = tasks_details_map[unique_key]["estimated_time"]
detail['total_tracked_time'] = tasks_details_map[unique_key]["total_tracked_time"]
# append to global table
if(all_time_record_details):
print(f".. Data for {project_id} saved! ..")
all_data = all_data + all_time_record_detailsReporting and Output
In the final part of the script, after gathering and organizing all the time tracking data from Active Collab, we move on to create a report from this data. We do this by turning our collected data into a DataFrame, a kind of table that’s very easy to work with in Python, especially with the help of the pandas library. To make sharing easy, we save this table as an Excel file.
# Create a DataFrame from the projects_reports list
projects_df = pd.DataFrame(all_data)
# Write the DataFrame to an Excel file
current_time = datetime.now()
timestamp_str = current_time.strftime("%Y%m%d-%H%M%S")
excel_path = f"output/report2_times_{timestamp_str}.xlsx"
projects_df.to_excel(excel_path, index=False)
print(f"Report saved to {excel_path}")
end_time = time.perf_counter()
# Calculate the difference
duration = end_time - start_time
print(f"Total running time: {duration:.6f} seconds")
print(f"Total time records across all projects: {total_time_records}")Debug function
Now let’s talk about a special function in our script called save_json_with_timestamp. Here’s what it does: whenever our script has gathered all the information for a project, this function steps in to save that data.
For example, if we were saving data for project number 123 on February 25, 2024, the file might be named something like time_records_20240225123015_123.json. This name tells us the data was saved on February 25, 2024, at 12:30:15, and it’s about project 123.
def save_json_with_timestamp(data, project_id, file_path_prefix='data/time_records_'):
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
# Defining the complete file path
file_path = f'{file_path_prefix}{timestamp}_{project_id}.json'
# Saving the JSON data to the specified file
with open(file_path, 'w') as file:
json.dump(data, file, indent=4)
print("File saved at:", file_path)
Summary
In this guide, we went through a Python script that helps us work with ActiveCollab, a tool for managing projects and tracking how much time tasks take. This script is great for people who want to get a clear picture of their work and find ways to manage their projects better.
We made sure that time spent on the same task by the same person was put together. This made our data cleaner and easier to understand. We also added extra details like how much time we planned to spend on tasks versus how much time we actually spent. This helps us see if we’re working as efficiently as we hoped. If you are looking for a web development company just contact us!


















